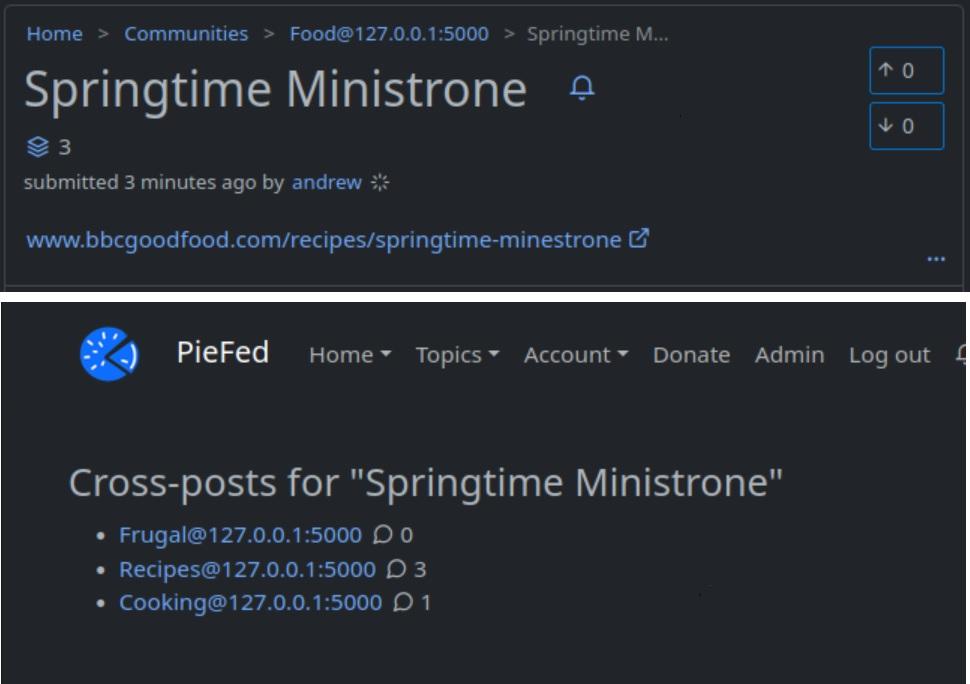
I've been thinking about what to do about cross-posts (e.g. where the same link is uploaded to both fediverse@lemmy.world and fediverse@lemmy.ml).
In terms of them being annoying, I don't yet know what to do about that.
My progress so far, and what it requires:
The Community table has an extra field (xp_indicator), for the field which determines if something is a cross-post or not. It defaults to URL, but it could be the title for communities like AskLemmy.
The Post table has an extra field (cross_posts), which is an array of other post ids (Note: this would lock PieFed into using Postgresql)
New posts, for local and ActivityPub, are checked to see if they are a cross-post, and the relevant posts are updated. This also happens for local edits and AP Update. In the DB, the posts in the screenshot looks like:
-[ RECORD 1 ]----------------------------------------------------------
id | 27
title | Springtime Ministrone
url | https://www.bbcgoodfood.com/recipes/springtime-minestrone
cross_posts | {28,29,30}
-[ RECORD 2 ]----------------------------------------------------------
id | 28
title | Springtime Ministrone
url | https://www.bbcgoodfood.com/recipes/springtime-minestrone
cross_posts | {27,29,30}
-[ RECORD 3 ]----------------------------------------------------------
id | 29
title | Springtime Ministrone
url | https://www.bbcgoodfood.com/recipes/springtime-minestrone
cross_posts | {27,28,30}
-[ RECORD 4 ]----------------------------------------------------------
id | 30
title | Springtime Ministrone
url | https://www.bbcgoodfood.com/recipes/springtime-minestrone
cross_posts | {27,28,29}
In the UI, posts with cross-posts get an extra icon, which when clicked bring you to another screen (similar to 'other discussions' in Reddit)
In terms of hiding duplicate posts from the feed, I don't yet know. If it was up to the back-end, it would require some extra DB activity that might be unacceptable speed-wise. This update would mean though, that a future API could provide a response similar to Lemmy for posts, so apps/frontends could merge duplicates the same way some of them do for Lemmy. Likewise, if there was a 'Hide posts marked as read' feature, it could regard any post ids in the cross_posts field as also being Read.
I have to wait a few days until the quota on my ngrok account resets (something in the Fediverse went crazy, I'd guess), so I thought I'd share here in the meantime. Also, it means the PR doesn't come out of the blue, and it can be discussed beforehand.
(also: it turns out I can't spell 'minestrone')