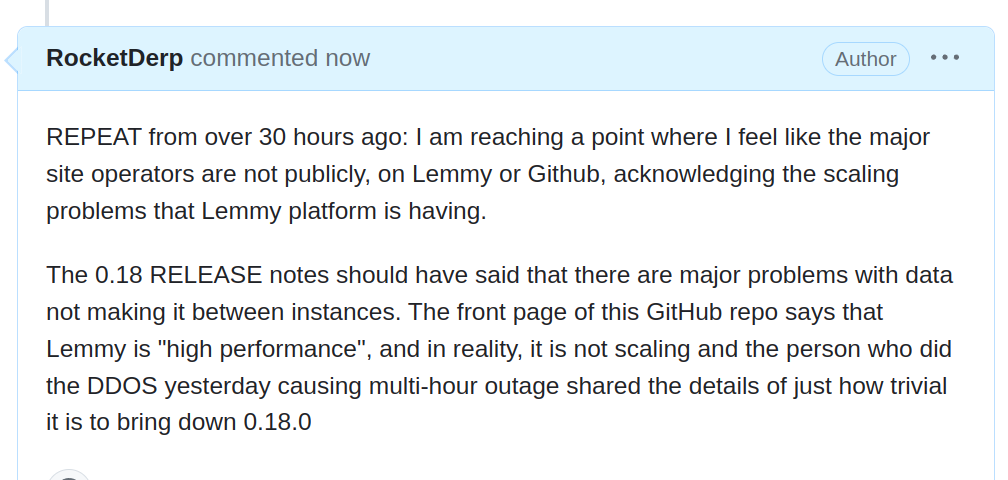
Lemmy.ml front page has been full of nginx errors, 500, 502, etc. And 404 errors coming from Lemmy.
Every new Lemmy install begins with no votes, comments, postings, users to test against. So the problems related to performance, scaling, error handling, stability under user load can not easily be matched given that we can not download the established content of communities.
Either the developers have an attitude that the logs are of low quality and not useful for identifying problems in the code and design, or the importance of getting these logs in front of the technical community and trying to identify the underlying patterns of faults is being given too low of a priority.
It's also important to make each log of failures identifiable to where in the code this specific timeout, crash, exception, resource limit is encountered. Users and operations personnel reporting generic messages that are non-unique only slow down server operators, programmers, database experts, etc.
There are also a number of problems testing federation given the nature of multiple servers involved and trying not to bring down servers in front of end-users. It's absolutely critical that failures for servers to federate data be taken seriously and attempts to enhance logging activities and triangulate causes of why peer instances have missing data be track down to protocol design issues, code failures, network failures, etc. Major Lemmy sites doing large amounts of data replication are an extremely valuable source of data about errors and performance. Please, for the love of god, share these logs and let us look for the underlying causes in hard to reproduce crashes and failures!
I really hope internal logging and details of the inner workings of the biggest Lemmy instances is shared more openly with more eyes on how to keep scaling the applications as the number of posts, messages, likes and votes continue to grow each and every day. Thank you.
Three recently created communities: !lemmyperformance@lemmy.ml -- !lemmyfederation@lemmy.ml -- !lemmycode@lemmy.ml