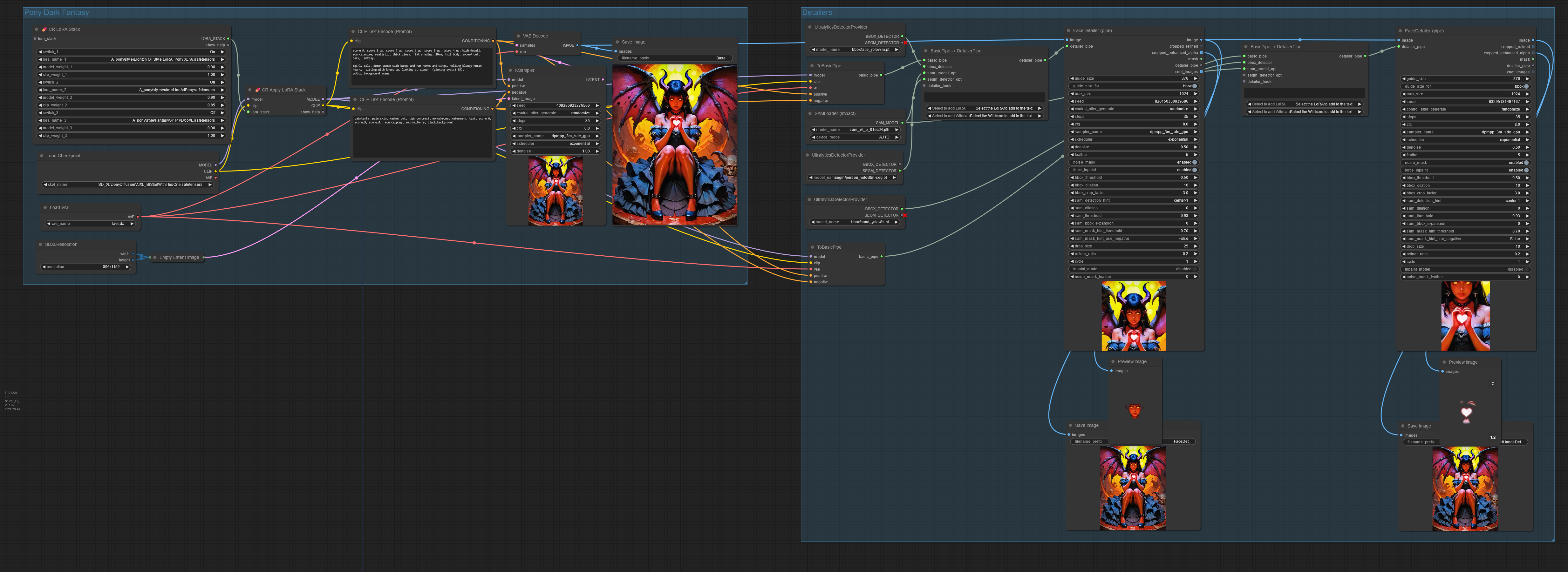
I've been trying to transition from SD1.5 to SDXL for a while, but old prompting habits die hard.
Even more difficult was finding a model to produce the look I prefer. Most seem to love realism, 3D pixar style, anime, and super airbrushed.
If you have any tips for SDXL models, loras, prompting for this style, etc. please let me know!
parameters:
1girl, demon woman with bangs and ram horns and wings, holding bloody human heart, solo, sitting with knees up, (full body:0.6), looking at viewer, (dark fantasy theme:1.1) (glowing eyes:1.05), thick lines, flat shading
Negative prompt: low quality, deformed, embedding:negativeXL_D, embedding:unaestheticXL_Sky3.1,
Steps: 10, Sampler: dpmpp_3m_sde_simple, CFG scale: 1.0, Seed: 212036223314935, Size: 1024x1024, Model hash: 268a170aa6, Model: grogmixTURBO_v10
(and some inpainting/upscaling)