I'm curious how it will do on the private benchmark that ai explained made. I think it was called simple bench?
this post was submitted on 12 Sep 2024
14 points (93.8% liked)
Technology
1348 readers
184 users here now
Which posts fit here?
Anything that is at least tangentially connected to the technology, social media platforms, informational technologies and tech policy.
Rules
1. English only
Title and associated content has to be in English.
2. Use original link
Post URL should be the original link to the article (even if paywalled) and archived copies left in the body. It allows avoiding duplicate posts when cross-posting.
3. Respectful communication
All communication has to be respectful of differing opinions, viewpoints, and experiences.
4. Inclusivity
Everyone is welcome here regardless of age, body size, visible or invisible disability, ethnicity, sex characteristics, gender identity and expression, education, socio-economic status, nationality, personal appearance, race, caste, color, religion, or sexual identity and orientation.
5. Ad hominem attacks
Any kind of personal attacks are expressly forbidden. If you can't argue your position without attacking a person's character, you already lost the argument.
6. Off-topic tangents
Stay on topic. Keep it relevant.
7. Instance rules may apply
If something is not covered by community rules, but are against lemmy.zip instance rules, they will be enforced.
Companion communities
!globalnews@lemmy.zip
!interestingshare@lemmy.zip
Icon attribution | Banner attribution
founded 11 months ago
MODERATORS
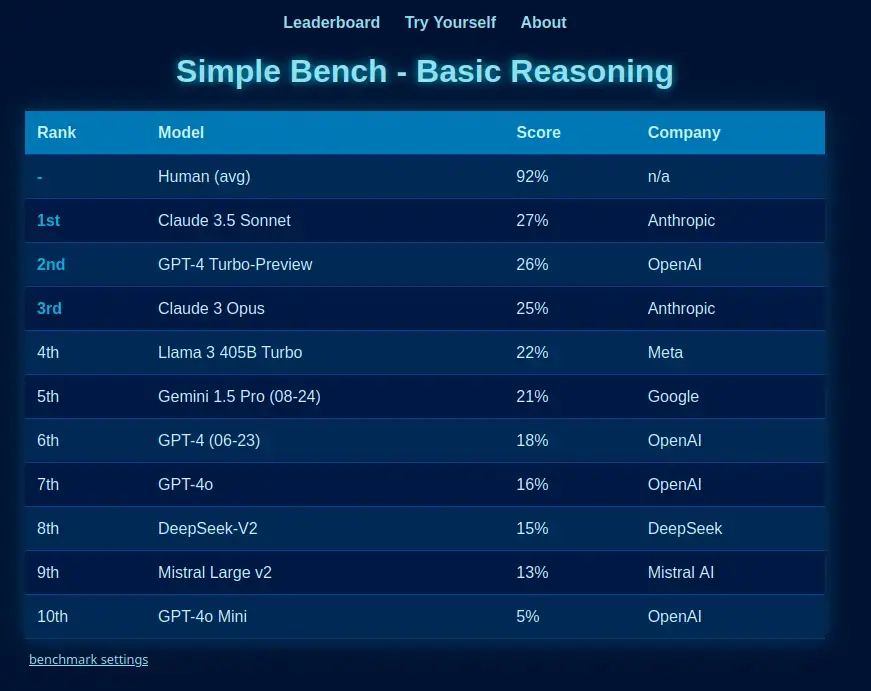
This is one stat I've found
https://simple-bench.com/index.html I was referring to this benchmark specifically because the point of it is to benchmark the actual reasoning capabilities of LLMs:
Simple bench is the only reasoning benchmark written in natural language at which English-speaking humans (and yes, even 'smart highschoolers') can score 90%+, while frontier LLMs get less than 50%. It is an encapsulation of the reasoning deficit found in AI like ChatGPT.
These questions are fully private, preventing contamination, and have been vetted by PhDs from multiple domains, as well as the author - Philip, from AI Explained - who first exposed the numerous errors in the MMLU (Aug 2023). This was celebrated by, among others Andrej Karpathy.
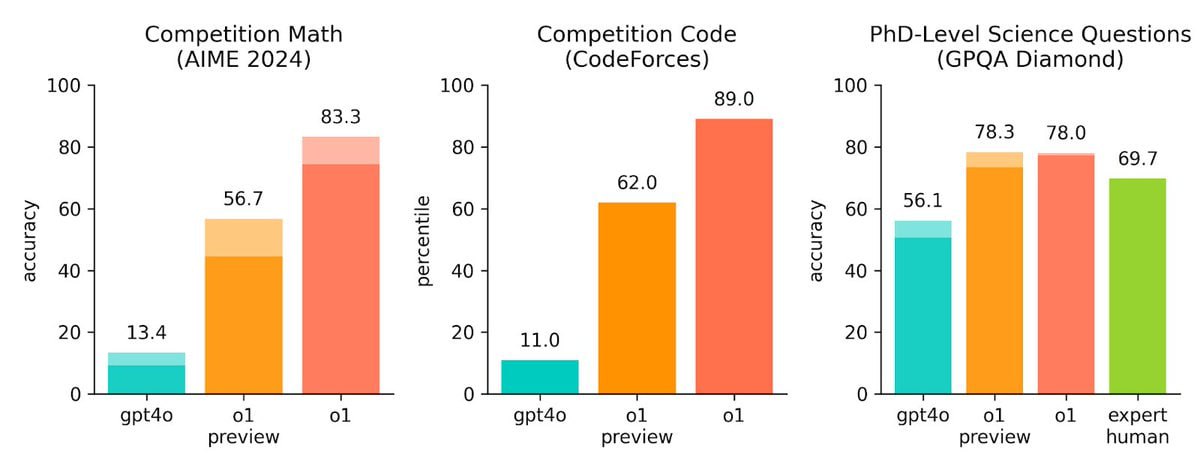
“The model is definitely better at solving the AP math test than I am, and I was a math minor in college,” OpenAI’s chief research officer, Bob McGrew, tells me. He says OpenAI also tested o1 against a qualifying exam for the International Mathematics Olympiad, and while GPT-4o only correctly solved only 13 percent of problems, o1 scored 83 percent.
That's still unreliable enough that I wouldn't trust it to actually do anything. If it scoured its database for a trigonometry textbook and cited a solution for a problem which was as correct as any web calculator, cool. That'd be as useful as google was in 2010. 83% is the kind of score I get on advanced mathematics tests when I have no idea what I'm doing but half-remember the basic steps to get an answer.
You get an 83% if you don't know what your are doing?
I wish my scores were as high in those situations...
no it doesn't have reasoning abilities. It just replicates you trying to coax it into giving you something decent, hides the process from you, and then charges you for it.