After setting up my own Lemmy server, I've been intrigued by the server logs. I was surprised to see some search engines already start to crawl my instances despite it having very little content.
I've noticed that most requests seem to come in from IPv4 addresses, despite my server having both an IPv4 and an IPv6 address. This made me wonder.
IPv4 addresses are getting more scarce by the day and large parts of the world have to share an IPv4 address to get access to older websites. This often leads to unintended fallout, such as thousands of people getting blocked by an IP ban from a site admin that doesn't know any better, as well as anti-DDoS providers throwing up annoying CAPTCHA pages because of bad traffic coming from the shared IP address. Furthermore, hosting a Lemmy server of your own is impossible behind a shared IP address, so IPv6 is the only option.
IPv6 is the clear way forward. However, many people haven't configured IPv6 for their hosts. People running their own Lemmy instances behind an IPv6 address won't be able to federate with those servers, and that's a real shame.
Looking into it
So, I whipped up this quick Python script:
import requests
import sys
import socket
from progress.bar import Bar
lemmy_host = sys.argv[1]
site_request = requests.get(f"https://{lemmy_host}/api/v3/site").json()
hosts = site_request['federated_instances']['linked']
ipv4_only = []
ipv6_only = []
both = []
error = []
with Bar('Looking up hosts', max=len(hosts)) as bar:
for host in hosts:
host = host.strip()
try:
dns = socket.getaddrinfo(host, 443)
except socket.gaierror:
error.append(host)
has_ipv4 = False
has_ipv6 = False
for entry in dns:
(family, _, _, _, _) = entry
if family == socket.AddressFamily.AF_INET:
has_ipv4 = True
elif family == socket.AddressFamily.AF_INET6:
has_ipv6 = True
if has_ipv4 and has_ipv6:
both.append(host)
elif has_ipv4:
ipv4_only.append(host)
elif has_ipv6:
ipv6_only.append(host)
else:
error.append(host)
bar.message = f"Looking up hosts (B:{len(both)} 4:{len(ipv4_only)} 6:{len(ipv6_only)} E:{len(error)})"
bar.next()
print(f"Found {len(both)} hosts with both protocols, {len(ipv6_only)} hosts with IPv6 only, and {len(ipv4_only)} outdated hosts, failed to look up {len(error)} hosts")
This script fetches the instances a particular Lemmy server federates with (ignoring the blocked hosts) and then looks all of them up through DNS. It shows you the IPv4/IPv6 capabilities of the servers federating with your server.
I've run the script against a few popular servers and the results are in:
Results
| Server |
IPv6 + IPv4 |
IPv6 only |
IPv4 |
Error |
Total |
| Lemmy.ml |
1340 |
3 |
1903 |
215 |
3461 |
| Beehaw.org |
807 |
0 |
1105 |
74 |
1986 |
| My server |
202 |
0 |
312 |
4 |
518 |
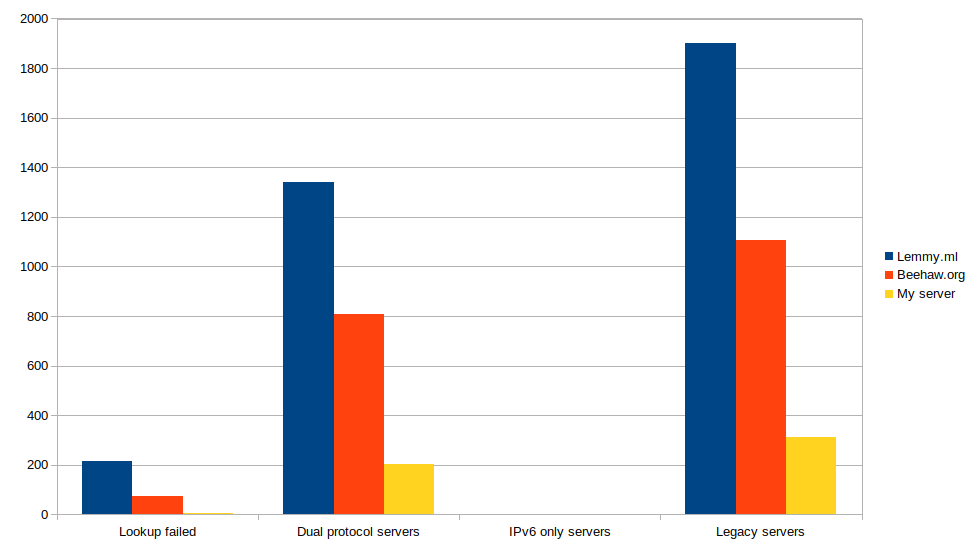
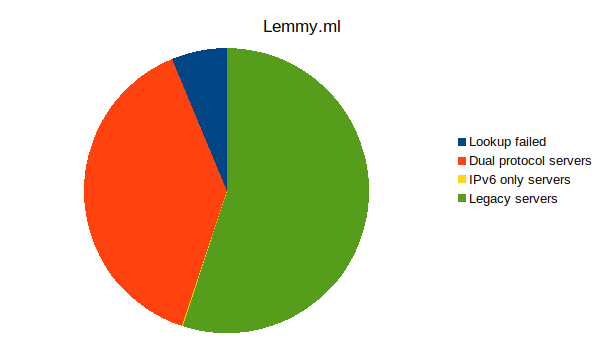
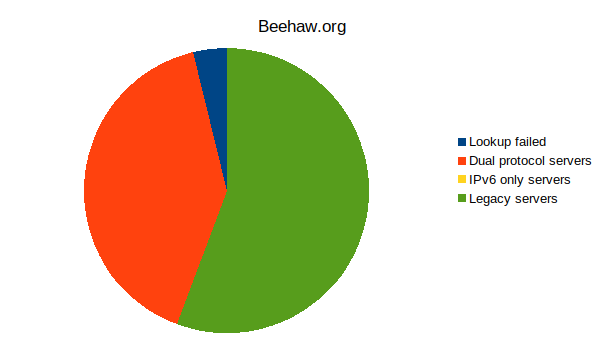
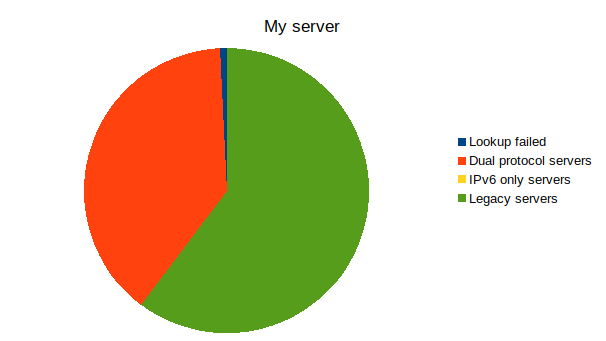
It seems that over half (55%+) the servers on the Fediverse aren't reachable over IPv6!
I'm running my own server, what can I do?
Chances are you've already got an IPv6 address on your server. All you need to do is find out what it is (ip address show in Linux), add an AAAA record in your DNS entries, and enable IPv6 in your web server of choice (i.e. listen [::]:443 in Nginx). Those running a firewall may need to allow traffic through IPv6 as well, but many modern firewalls treat whitelist entries the same these days.
Some of you may be running servers on networks that haven't bothered implementing IPv6 yet. There are still ways to get IPv6 working!
Getting IPv6 through Tunnelbroker
If you've got a publicly reachable IPv4 address that can be pinged from outside, you can use Hurricane Electric's Tunnelbroker to get an IPv6 range, free of charge! You get up to five tunnels per account (each tunnel with a full /64 network) and a routed /48 network for larger installations, giving you up to 65k subnets to play with!
There are lots of guides out there, some for PfSense, some for Linux, some for Windows; there's probably one for your OS of choice.
Getting IPv6 behind CGNAT
Getting an IPv6 network through a tunnelbroker service behind CGNAT is (almost) impossible. Many ISPs that employ CGNAT already provide their customers with IPv6 networks, but some of them are particularly cheap, especially consumer ISPs.
It's still possible to get IPv6 into your network through a VPN, but for serving content you'll need a server with IPv6 access. You can get a free cloud server from various cloud providers to get started. An easy way forward may be to host your server in the cloud, but if you've got a powerful server at home, you can just use the free server for its networking capabilities.
Free servers are available from all kinds of providers, such as Amazon(free for a year), Azure(free for a year), Oracle(free without time limit). Alternatively, a dedicated VPS with IPv6 capabilities can be as cheap as $4-5 per month if you shop around.
You can install a VPN server on your cloud instance, like Wireguard, and that will allow you to use the cloud IPv6 address at home. Configure the VPN to assign an IPv6 address and to forward traffic, and you've got yourself an IPv6 capable server already!
There are guides online about how to set up such a system. This gist will give you the short version.
Final notes
It should be noted that this is a simple analysis based on server counts alone. Most people flock to only a few servers, so most Lemmy users should be able to access IPv6 servers. However, in terms of self hosting, these things can matter!

I already feel like I have to keep sticking my neck out to get them to question if using the ORM and a dozen JOIN statements isn't a problem.... but I guess I'll link it: https://github.com/LemmyNet/lemmy/pull/3900
As stated on my Lemmy user profile, I'm "RocketDerp" on GitHiub.
Honestly, the reason I keep making noise is because I'm sick of Lemmy crashing all the time when I come to use it... and I am on many servers that this happens. I really am not trying to piss off the developers, I even said I felt like I am being hazed, and I feel like hazing in general might explain what is going on with how much they are avoiding the elephant in the ROOM that ORM and a dozen JOIN might be the cause! Let alone the lack of Redis or Memcached addition being avoided, that's a second elephant on the second floor tap-dancing.... GitHub Issue 2910 was the straw that broke my back weeks ago, it took months for them to address it when it could be fixed in a couple hours (and it was weeks before the Reddti API deadline at the end of June.... and issue 2910 was neglected). The whole thing was a nightmare for me to watch...